Stepping into MapReduce
in Technical
Yesterday I have been immersed in a MapReduce assignment for my data centre class, so this week I want to give you guys a taste of MapReduce, one of the most used data processing frameworks, and also base of many other great frameworks.
Intro to MapReduce
First of all, MapReduce falls into the umbrella of “Big Data”, which has been hot for the past few years with the rise of AI, so for the very least it is worth taking a look over it. Usually MapReduce deals with a large amount of data, of magnitude of GB and above, that usually follows a “logical record” format. Normally this just means we can treat data as lines of strings, one at a time. Later in this post, I will have an example to explain everything, but first let’s take a look at MapReduce in a high-level of abstraction.
Principle
From the highest level, MapReduce exposes a pipeline-like* structure, and usually is used for batch processing of large data. Note that there is an asterisk there, we will address it later. Going a little bit deeper, and we see MapReduce consists of these following stages:
Map: for each line of String, extract the Key and the Value.
Shuffle: sort all the key value pairs so that all values with the same key stick together, usually in ascending order. (This step is usually hidden from us developers)
Reduce: for each key, reduce all the values associated with it down to one.
Generate output: this is not really part of MapReduce, but you still need it to get meaningful result.
You might wonder what is this “Key Value” thing. Unfortunately it is not a definitive thing. These are developer-defined types that caters to their goals. For example, if we are to count the number of occurrences for each word in a novel, the key would be each word, and the value would be the number of times they appear in the book. Again these will be a lot clearer after you see the example later.
Before I go into the example, let me talk about a few things. First the asterisk about pipeline. Also it does seems like each of the steps above cannot proceed until the previous one is done, but behind the scenes the transition is streamed. The Shuffler will start working before getting all the mapper output, and so forth. So it isn’t that bad in performance.
Speaking of performance, MapReduce is very efficient, especially when used in a cluster in a data centre. The reason for this is that the steps needn’t to be done on just one process, or one computer in general. Take the example above, if we partition the novel into many little “shards” and distribute them to many computers, and run mapper and reducers on each of them, we can get it done a lot quicker, in a highly parallelised paradigm.
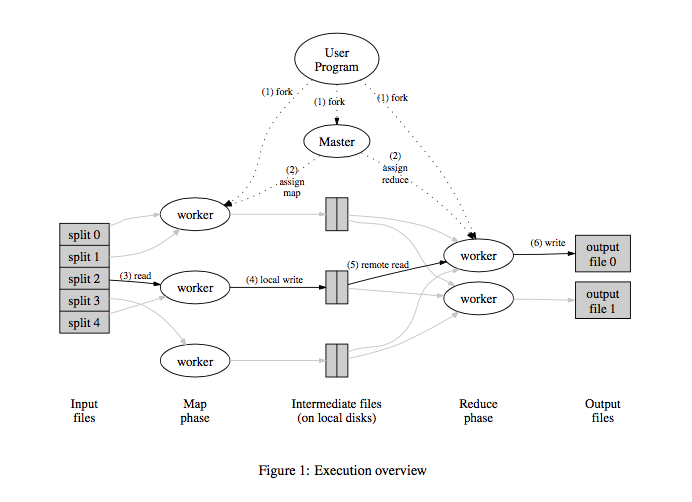
from the original Google paper
Example
Now let’s look at a real world example. As a disclaimer, this example is put together by my professor, Prof. Don Smith, I cannot take any credit.
First let’s take a look at the data. This is a typical line: ADU: 1208557512.904791 190.48.193.183.443 < 46.64.134.209.2872 641 SEQ 0.000757
This records a package sent from 46.64.134.209 at port 2872 to 190.48.193.183 at port 443, with 641 bytes sent over. Our goal is to count the number of sends for each IP present.
Mapper
import java.io.IOException;
import java.util.*;
import java.io.*;
import java.net.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.mapreduce.Mapper;
public class HostCountMapper
extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] tokens = line.split("\\s");
String sendingIP = new String();
int last_dot;
// get the sending IP address.port field
if (tokens[3].equals(">")) {
sendingIP = tokens[2];
} else {
sendingIP = tokens[4];
}
// eliminate the port part
last_dot = sendingIP.lastIndexOf('.');
sendingIP = sendingIP.substring(0, last_dot);
// output the key, value pairs where the key is an
// IP address 4-tuple and the value is 1 (count)
context.write(new Text(sendingIP), new IntWritable(1));
}
}
Note the type of the Mapper. The first LongWritable is the index of line in the file, which usually doesn’t get used; the second Text is the line itself, like the one above. The following two types are the key and value for the mapper output. Text for the sending IP, IntWritable for the send occurrence, in our case would be 1.
The rest of the Mapper is pretty straightforward. After some string processing, we got the sending IP, the last thing we need to do is write it into context, which gets shuffled and sorted automatically by the framework.
Next to the Reducer
Reducer
import java.util.*;
import java.io.*;
import java.net.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.mapreduce.Reducer;
public class HostCountReducer
extends Reducer<Text, IntWritable, Text, LongWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context)
throws IOException, InterruptedException {
long count = 0;
// iterate through all the values (count == 1) with a common key
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new LongWritable(count));
}
}
Again the type of Reducer. The first two match the output from the mapper(the Iterable<> is because we have got many values for one key, natrually). The following two are the final output type, Text for the sending IP again, LongWritable for the total number of 1s we got from Mapper.
The body is simple again, just adding the 1s together, and finally writing it back into context again, which later will be merged into a final output.
Master Control
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class HostCount {
public static void main(String[] args) throws Exception {
if (args.length != 2) {
System.err.println("Usage: HostCount <input path> <output path>");
System.exit(-1);
}
//define the job to the JobTracker
Job job = Job.getInstance();
job.setJarByClass(HostCount.class);
job.setJobName("Host Counts");
// set the input and output paths (passed as args)
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// set the Mapper and Reducer classes to be called
job.setMapperClass(HostCountMapper.class);
job.setReducerClass(HostCountReducer.class);
// set the format of the keys and values
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// set the number of reduce tasks
job.setNumReduceTasks(10);
// submit the job and wait for its completion
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
There isn’t much to explain really. Master control sets the config of the job, with the most important setting: number of reducers, which impacts the performance of the job.
Conclusion
The example above, as you probably think, is pretty simple, but it should give you a clear idea of what MapReduce is under the hood. There are many other frameworks built on top of MapReduce, such as Spark, which adds more features here and there.
If you want to know more about MapReduce, take a look at Apache Hadoop Official site for MapReduce, and TutorialsPoint website for a more comprehensive image.